Infrastructure at Furality
2022-08-17
You can find the slide deck here
Back in November of 2021, Furality Legends convention took place, and I attended along with my SO Becki. It was an interesting experience, and I bought a VR headset (an Oculus Quest 2) about halfway through to properly immerse myself. During the tech enthousiast meetup, a volunteer of the convention popped in, and while speaking to another attendee mentioned they were open to new volunteers. Inspired, and eager to improve my skills in DevOps (I was employed at CircleCI, about to transition to my current employer), I promptly sent an email in with a very short introduction, and ended up joining the convention's DevOps department. Despite the name, the DevOps team encompasses all web-related development (it's important to distinguish this from the Unity/world development team) including the F.O.X. API (a currently monolithic PHP application), web frontend for both the portal and main organisation website, and a few other pieces required to run the convention smoothly. I landed on the infrastructure team, a hybrid of Platform and Developer Experience. Coming off of Legends, the team lead, Junaos, was starting to investigate alternate means of hosting the backends and frontends that wasn't just a pile of servers (you can see what our infrastructure used to look like here during the DevOps panel at Legends), so I joined at a really opportune time for influencing the direction we took.
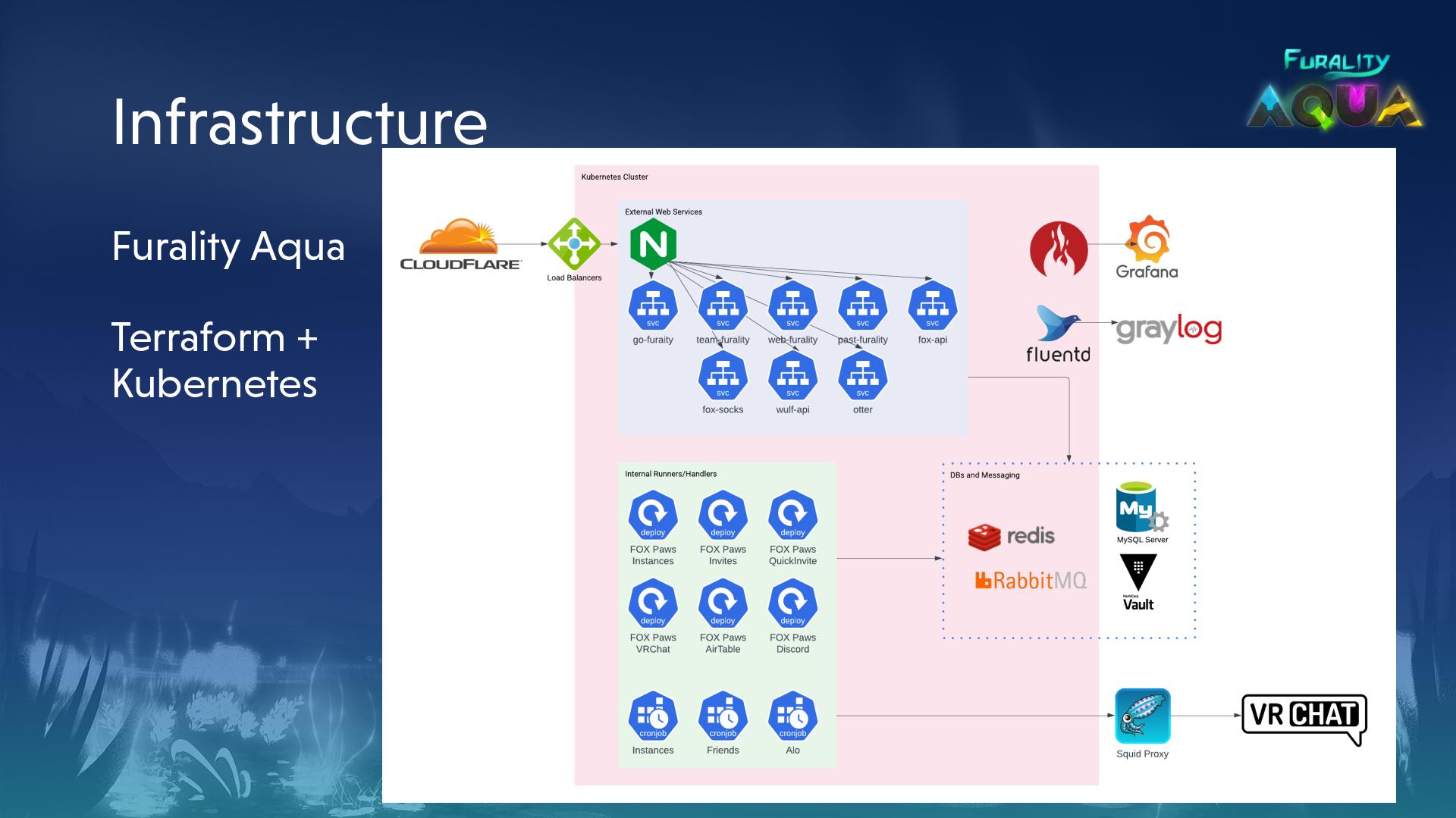
While the infrastructure team is also responsible for maintaining the streaming infrastructure required to run the convention club, live stream, live panels, and more, this is relatively hands off, and I didn't have a ton of involvement in that side of things. Alofoxx goes into more detail during the panel.
The technical requirements of Furality are somewhat unique. We have a few events per year, with a crazy amount of activity (in the ~150req/s range to our API during Aqua) during a weekend then very little until the next event. It's entirely made up of volunteers, so scheduling things can be tricky and while there is some overlap in availability it can be tough to ensure people are online to monitor services or fix bugs, especially during the offseason. With these things in mind, some key focuses emerge:
- Aggresive auto scaling, both up and down
- Automate as much as possible, especially when getting code into production
- Monitor everything
Of those three, I think only the 1st point is really unique to us. Points 2 and 3 can apply pretty widely to other tech companies (the DevOps department is, operationally, a small tech startup).
We picked Kubernetes to help solve these three focuses, and I think we did pretty damn well. But before I explain how I came to that conclusion, let's dive into the points a little deeper, talk about how Kubernetes addresses each issue, and maybe touch on why you wouldn't want to use Kubernetes.
Aggresive auto scaling, both up and down
As mentioned, Furality has a major spike of activity a few times a year for a weekend (with some buffer on either side), followed by a miniscule amount of user interaction in between. While this is doable with provisioned VPSs through Terraform and custom images built with Packer, it feels a little bit cumbersome. Ideally, we define a few data points, and the system reacts when thresholds are met to scale up the number of instances of the API running. Since the API is stateless (everything feeds back to a single MySQL database), we aren't too worried about things being lost if a user hits one instance then another.
One perk of this system being for a convention is we can examine the scheduled events taking place and use that to predict when we need to pay particular attention to our systems. That 150 requests per second figure was rounding down during our opening ceremonies, when attendees were flocking to the portal to request invites to worlds, intent on watching the stream. The backend team had the foresight to implement a decent caching layer for some of the more expensive data retrieval operations, and all said and done there was no real "outage" due to load (with the definition of outage being a completely inaccessible service or website). Things just got a bit slow as our queue consumers sending out invites fell behind a bit - a bit of tweaking to the scaling sorted it out - and some would sometimes crash outright.
Part of the way through building out the infrastructure, I was
questioning our decision to opt for Kubernetes over something else. But
it actually proved to be a solid choice for our use case, especially for
scaling, since we could automatically scale the number of pods, and in
turn nodes for our cluster, by defining the few metrics we wanted to
watch (primarily looking at requests being handled by php-fpm and CPU
usage). We scaled up pretty aggresively, and maxed out at about 20
s-4vcpu-8gb DigitalOcean nodes. With a bit more tuning I'm sure we
could have optimised our scaling a little better, but we were intent on
ensuring a smooth experience for con-goers, and opted for the "if it
works" mentality.
Scaling down was a bit tricky. During the off season we need to keep nearly all the same services running, but with much smaller capacities to facilitate some of the portal and internal functionality, as well as ongoing development environments. Because the bulk of Furality's income happens during the convention, it's important to keep off-season costs low, and this is one of the reasons we opted for DigitalOcean as the server host. We ended up with a slightly larger cluster than we started out with pre-convention, even after aggresively scaling down and imposing resource limits on pods. Scaling down our database, which we sized up 3 times during the convention with no notable downtime, was also a bit tricky, as DigtalOcean has removed the ability to scale down via their API. Instead, we migrated the data manually to a smaller instance, doing various sanity checks before fully decomissioning the previous deployment.
Automate as much as possible, especially when getting code into production
It can be hard to wrangle people for code reviews or manually updating
deployments on servers. At one point, updating the F.O.X. API required
ssh'ing into individual servers and doing a git pull, or running an
Ansible playbook to run a similar command. This was somewhat error
prone, requiring human intervention, and could lead to drift in some
instances. To address this, we needed a way of automatically pushing up
changes, and having the servers update as required, while also making
sure our Terraform configuration was the source of truth for how our
infrastructure was set up.
To accomplish this, we built out Otter, which is a small application listening for webhooks from our CI/CD processes that will take the data it recieves and updates our Terraform HCL files with the new tag, opening a pull request for review. It's not a perfect system, still requiring some human intervention to not only merge the changes but also apply the changes through Terraform Cloud, but it was better than nothing, and let us keep everything in Terraform.

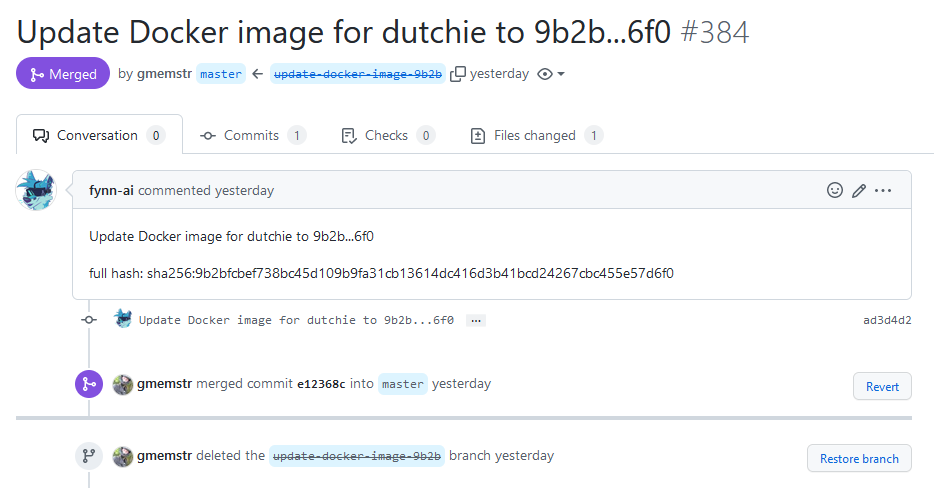
We also built out Dutchie, a little internal tool that gates our API documentation behind OAuth and rendering it in a nice format using SwaggerUI. It fetches the spec directly from the GitHub repository, so it's always up to date, and as a bonus we can fetch specific branches, estentially getting dev/prod/whatever else versioning very easily.
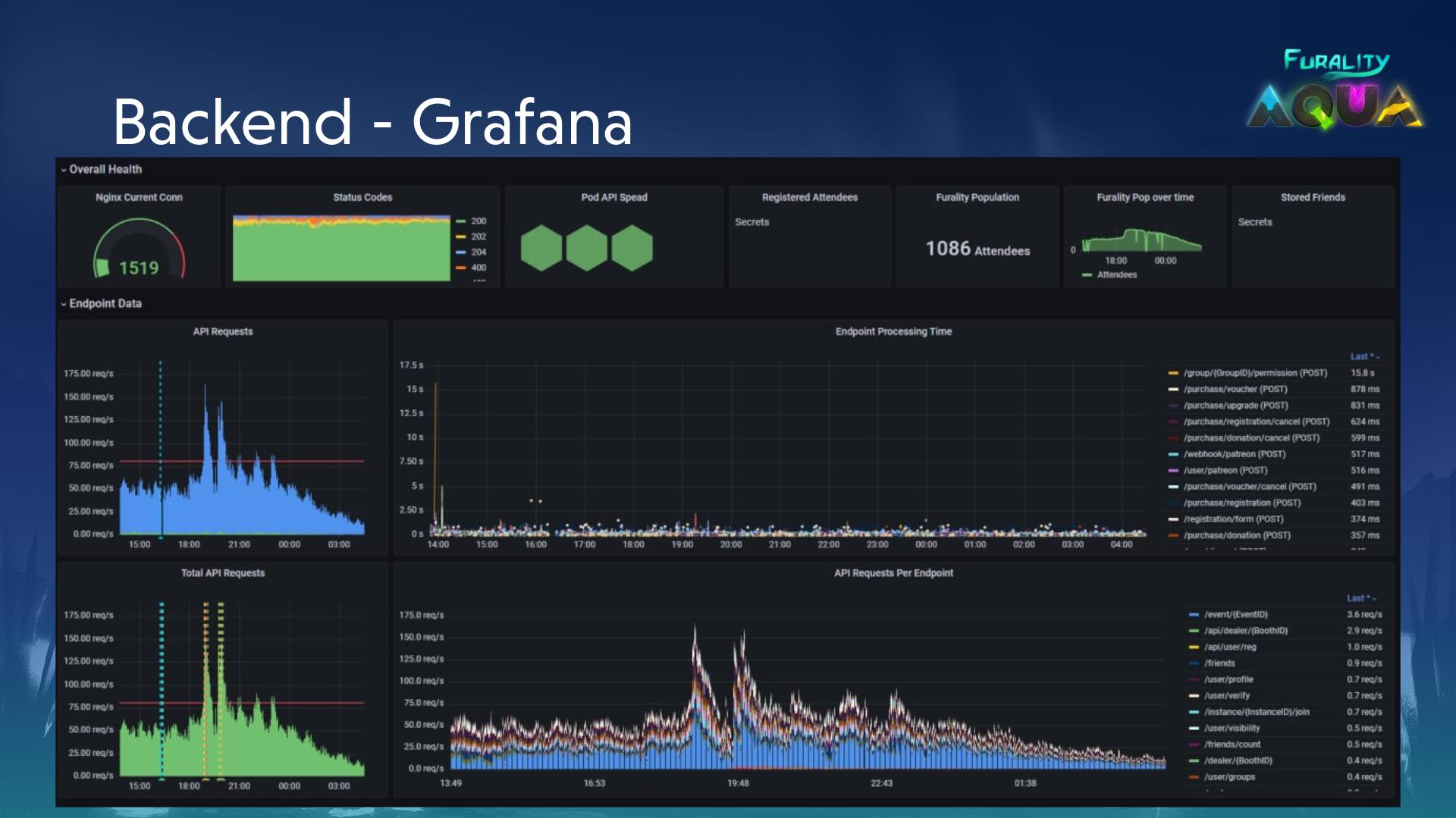
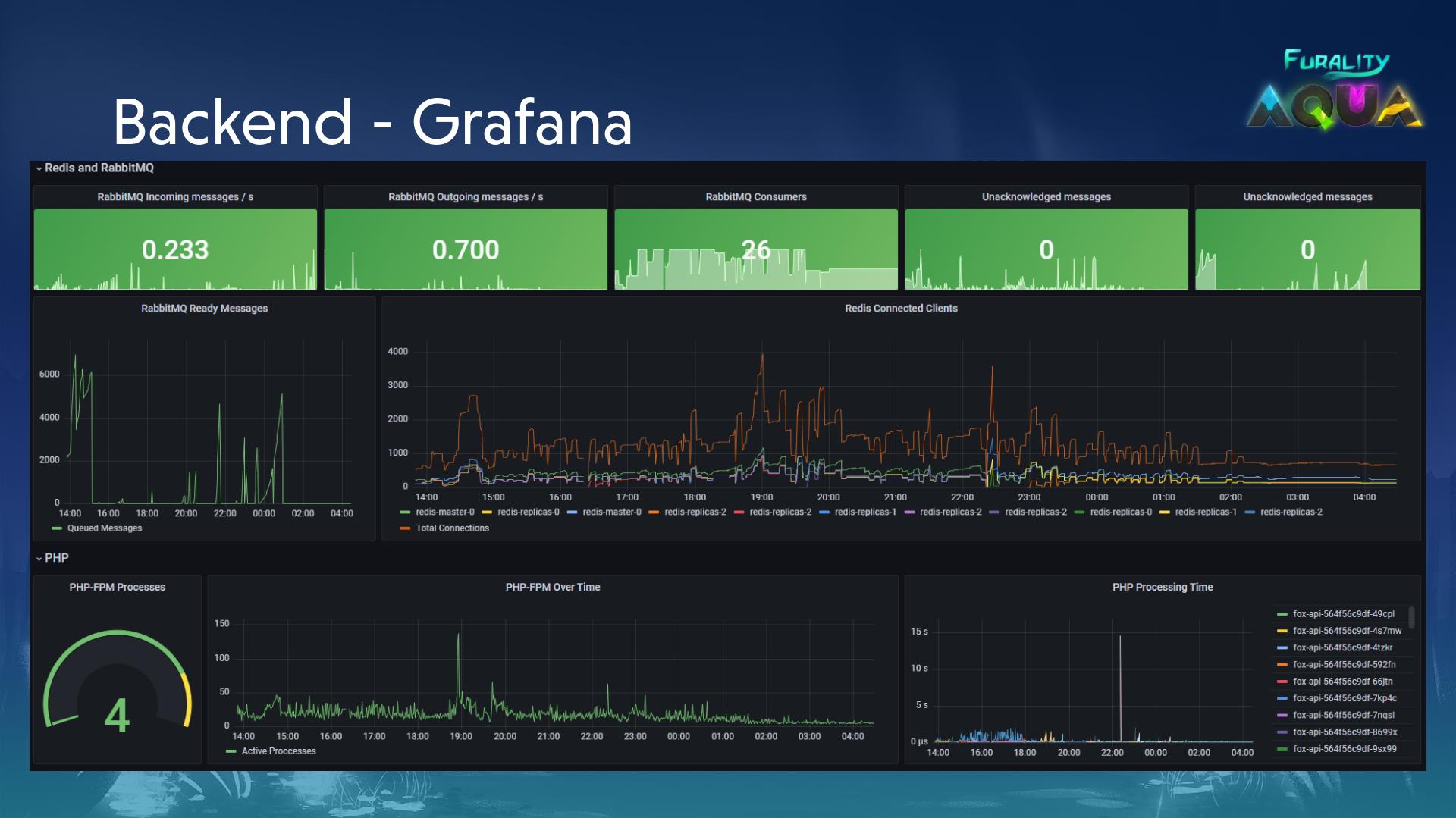
Monitor everything
We already had Grafana and Graylog instances up and running, so this is pretty much a solved problem for us. We have Fluentd and Prometheus running in the cluster (along with an exporter running alongside our API pod for php-fpm metrics) that feed into the relevant services. From there we can put up pretty dashboards for some teams and really verbose ones for ourselves.
What could have been done better?
From the offset, we opted to deploy a lot to our Kubernetes cluster, including our Discord bots, Tolgee for translations, and a few other internal services, in addition to our custom services for running the convention. Thankfully we had the foresight to deploy our static sites to a static provider, CloudFlare Pages. Trying to run absolutely everything in our cluster was almost more trouble than it was worth, such when a pod with a Discord bot would be killed and moved to another node (requiring the attached volume for the database to be moved), or the general cognitive load and demand of maintaining these additional services that didn't benefit much from running in the cluster. We're probably going to move some of these services out of our cluster, specifically the Discord bots, to free up resources and ensure a more stable uptime for those critical tools.
Another thing that we found somewhat painful was defining our cluster state in Terraform, rather than a Kubernetes-native solution. We ended up acruing a fair amount of technical debt in our infrastructure state repository and running everything through Terraform Cloud drastically slowed down pushing out updates to configurations. While it was nice to keep our configuration declaractive and in one place, it proved to be a significant bottleneck.
What happens next?
We don't really know! As it stands, I'm fairly confident our existing infrastructure could weather another convention, but we know there are some places we could improve, and the move did introduce a fair amount of technical debt that we need to clean up. For example, we're using Terraform to control everything from server provisioning to Kubernetes cluster, and want to move the management of our cluster to something more "cloud native" (our current focus is ArgoCD). There is also some improvements that could be done to our ability to scale down, and general cost optimisation. Now that we have a baseline understanding of what to expect with this more modern and shiney solution, we can iterate on our infrastructure and keep working towards an "ideal system", something you don't normally have the chance to do in a traditional full time employment role. Whatever it is we do, I'll be very excited to talk about it at the next DevOps panel.
If you have any questions, feel free to poke me on Twitter or on Mastodon.