Stop Scraping my Git Forge
2024-06-03
Amazonbot, please. It's too much.
I recently decided to dig into the webserver analytics for my self-hosted Git forge, which are provided by Cloudflare through my use of Tunnels to expose it to the wider internet. While generally I post my code under open source licenses to others can easily use it, learn from it, modify it, whatever they like, I do not like the idea that large corporations are taking this same code and putting it into a black box that is a machine learning model.
How this affects my use of the licenses I open source my code under, I'm unsure.
Corporations stealing, or using work without permission, for their machine learning models has been a discussion for a long while at this point. In general, I side with the creators or artists having their work taken. While I have used various machine learning "things" in the past, from ChatGPT to Copilot (the code one, not Copilot+) to Stable Diffusion, it was mostly from the standpoint of curiousity - see what it could do, but not use whatever it spat out in any serious capacity. Text generation models were the most useful in my case. Organising thought or recalling specific terminology/techniques could sometimes be tricky, and being able to rubber duck with it proved handy as a springboard to go do "serious" research with a search engine or technical documents. The key here, of course, being that what the text models gave me was not taken at face value, and instead used to reorient myself in the right direction. Stable Diffusion is an entirely different thing, and being friends with a number of artists I was generally uncomfortable using it even if I was getting crappy results.
But I digress, this isn't necessarily a post about my general feelings on machine learning. This is specifically about how corporations are gathering this data.
Looking at my analytics, it isn't uncommon to see some crawlers going through various pages to index them, and I'm usually okay with it since it can help discoverability for the purposes of learning how systems are put together (I'm much less worried about people actually using my software, although it is always a joy when someone does). But I saw a massive uptick in the amount of data (many gigabytes over a few days) that a certain Amazonbot (Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)) was pulling from git.gmem.ca and decided to take a slightly closer look. Quicky checking the link included in the user agent, it appears it's used for Alexa related queries, but Cloudflare Radar lists it as an "AI Crawler", which makes me suspect it's also feeding into whatever machine learning models they're building at AWS. This suspicion was further from the sheer amount of data and depth the crawler was pulling, pulling individual commits for projects (among other things). This did not impress me.
While I'm specifically calling out Amazonbot here, it wasn't the only crawler. The difference being it was the most notable crawler given the volume of requests. That said, the other crawlers didn't have any business crawling my git forge either, so...
I blocked them.

One WAF rule later, and I have all "Known bots" blocked from visiting my git forge. I was inclined to block IP ranges or ASNs, but ultimately decided against it. I generally believe that information should be freely accessible to any individual who seeks it out, but corporations are not individuals, and while I can easily handle the amount of traffic (given I had to look at logs to notice it should tell you something), it still places an unexpected and unecessary amount of strain on my infrastructure.
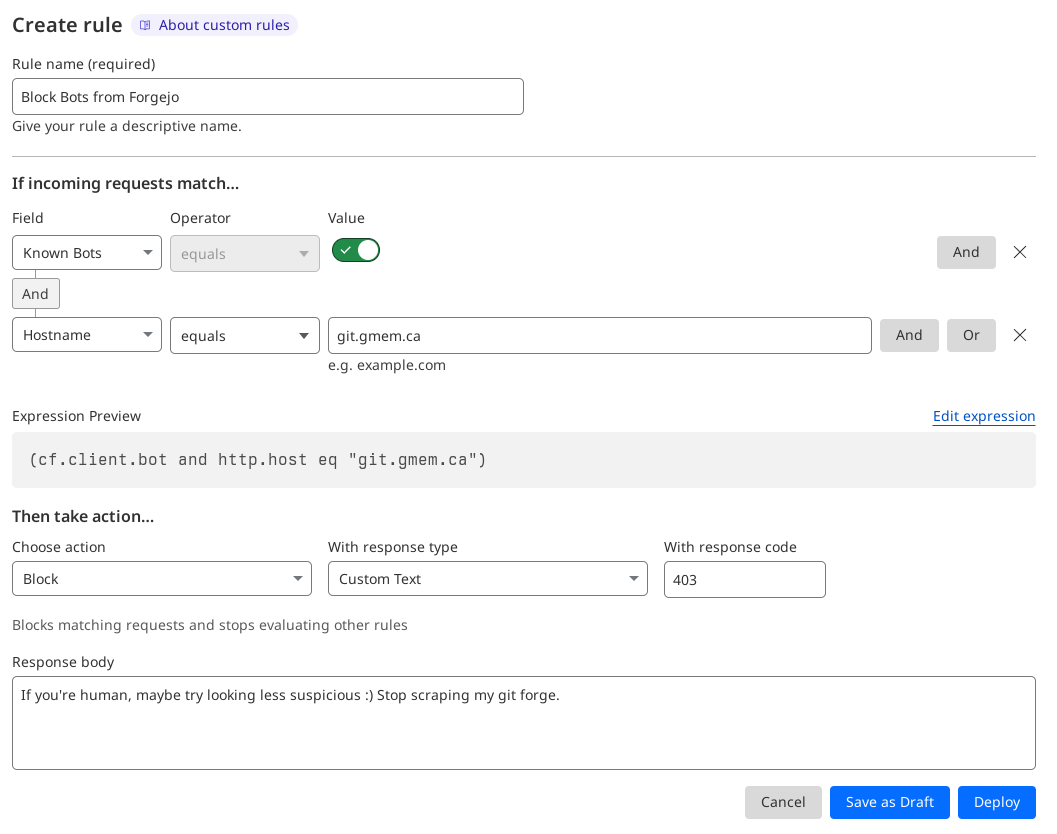
As of writing, the crawlers are still trying to crawl, and the WAF rule has blocked ~25,000 requests since I put the block in place (June 2nd 2024 5:15PM BST - June 3rd 2024 2:30PM BST). I'm resting a bit easier now, and would encourage others to look at their own logs to figure out whether their own instances are being scraped as well.